Table of Contents
- Introduction
- Build abstractions, not illusions
- 🌟 How to measure ROI and make your platform effect visible
- Build golden paths for day 50, not for day 1!
- 🌟 Backstage does not an internal platform make!
- The power of collaboration: Why platform engineers should engage in open source contributions
- Authorization at scale in platform environments
- Drift detection in multi-region AWS deployments for enterprises using DriftCTL
- Shorten the feedback loop: How to optimize developer experience and system design
- Why is it so hard to create a great Platform-as-a-Product?
- High-performing engineering teams and the Holy Grail
- 🌟 How to implement a developer platform in an organization with hundreds of existing services
- How to avoid burning your startup money on cloud costs!
- Conclusion
Introduction
PlatformCon 2023 happened between 8-9 June, there were more than 150 talks about Platform Engineering divided into the topics: Culture, tech, impact, stories or blueprints. I decided to share my notes about some talks that I watched and I would recommend you to watch the full talk if you get interested in the talk subject.
The post will be divided into sections and each one is referring to one talk. I prefixed the most insightful talks (for me) with a “🌟”, check them out!
Build abstractions, not illusions
When building platforms, one of our core objectives is reducing cognitive load. This can be achieved by building abstractions, which enables the user to focus on details of greater importance.
Often times, it is common to see ilussion being created instead of abstractions. What is the difference?
- Abstraction is removing or generalizing details to focus attention on details of greater importance.
- Illusion is removing or generalizing important details, which cause the user to be misled.
One of the main challenges when building platforms is hiding complexity without hiding important details.
Key take-aways:
- Platforms reduce cognitive load by exposing useful abstractions.
- Good abstractions form a cohesive language and useful mental model.
- Omitting relevant details is tempting but ends up with dangerous illusions.
🌟 How to measure ROI and make your platform effect visible
The best way to measure ROI is starting off with metrics. But what and how to measure?
The answer is simple: start with well-known frameworks. Something that “management can Google” and have proven impact with successful stories of another companies. For example: DORA, SPACE and Flow Framework. Using this well-known frameworks is an easier way to start instead of trying to create a new one, because management can understand how the existent framework works and what value does it brings.
Roadmap to ROIs
Proxy metrics
The key is to start with a couple of metrics and improve overtime. You shouldn’t start “boiling the whole ocean”.
There are some metrics that can be used as “Proxy metrics”, and can communicate well with management/executives in the company. Below are some examples of “proxy metrics”:
- Measuring Lead Time, you can use it as a proxy to Time to Market – if you reduce your Lead Time in 20%, it means that your Time To Market is reduced well.
- Measuring Wait Time to Review, you can use it as a proxy to Productivity – if you reduce your Review Time, it means that developers can deploy more frequently, feeling more productive.
Note that this is an example of “how to start” with the bare minumum and communicate with management. You should continuously improve these metrics, it isn’t an “one-off” effort.

It is important to keep measuring these metrics and compare it with the past. Ideally, you could extract valuable information about improvement by analysing how these metrics were in the past and how it improved overtime. Along with that, correlating this improvement with business outcomes.
Visibility
A key delivery is visibility. You should make effect by creating visibility of these metrics. Also, automating as much as you can to extract these metrics, you can turn this visibility “live”, updating day after day and reducing effort/toil to calculate them.
With this visibility in place, you could report it to right level adapting your communication based on the listener. If you are talking to your VP of engineering, he probably will care about more “low-level” metrics such as Review Time. But maybe the CEO is more interested in “high-level” ones, such as Time to Market and how to improve it.
With the business impact that the platform has, metrics and visibility in place to measure its ROI, we will build trust in this “platform transformation journey”. This trust will come back to the platform with more investment and improvements.
Build golden paths for day 50, not for day 1!
Most golden paths are focused on day 1. They focus only on the creation of the workload, but the problem is that this new workload will last for years.
So, it is important to create golden paths not only for day 1, but also for day 50, 100, 1000, etc. To make it possible, for every release of the workload, we should dynamically generate all necessary infrastructure and application configurations.
We need to treat every day like it’s the first day. We need to treat every deployment as if we were deploying the first time. By doing this, we can continuously standardize golden paths and reduce cognitive load.
Dynamically create configurations is possible when you have an abstraction description of your component, what resources it needs and what applications it depends on. One developer could describe, in an environment-agnostic way, how one workload depends on another workloads and resources.
Having this “Workload Specification” improves developer experience, because the configuration can be created dynamically depending on what he wants. For example, to deploy this specification to staging or a ephemeral environment, the change between these environments is as simple as a “git push”. Then the “platform orchestrator” will create, based on the context given by the developer, dynamically configurations.
This continuous and dynamic configuration is the opportunity to standardize any part of the Software Development Lifecycle. Could be creating a new workload or upgrading a database version, having a declarative specification of what the developer wants, the orchestrator will standardize how this operation is done.
The power of dynamic configuration management and designing golden paths in a decentralized way, along with the entire SDLC. Below is an image as example of benefits when there are standards for the entide SDLC:

🌟 Backstage does not an internal platform make!
Most platforms have the same dream:
- Reduce costs
- Increase speed
- Reduce risk
But, there are some enemies of the platform progress. One of the most significant ones is the learning curves and high cognitive load. Learning curves is huge in the platform engineering space – Kubernetes, CI/CD tools, Helm, Golang and the list goes; All enemies and the inherit of the abstractions built, makes the platform team deal with a lot of cognitive load.
In the last years, Backstage is increasing its popularity and a lot of platform teams are using is as a UI interface to the platforms. Backstage offers a powerful framework and a positive UX for internal customers. But in reality, Backstage brings a lot of problems to the platform team:
- How to deploy it
- How to secure it
- How to keep it updated with open source
- How to customise it (React, HTML, CSS)
Although Backstage is a powerful and awesome tool to drive UX, it doesn’t come for free. All of the topics above increase even more the cognitive load of platform teams, that was already high.
A common Backstage architecture can be seem below:
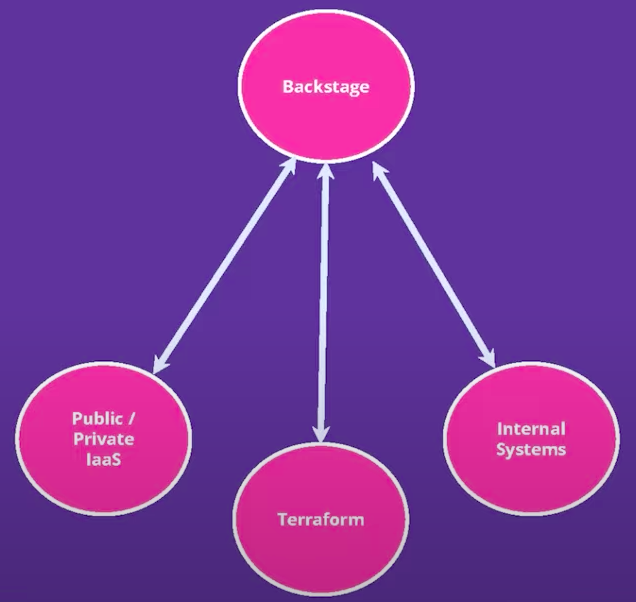
Backstage has a ton of plugins that can be plugged. But you need to be careful to not “Leaky the abstractions” by making your Backstage have too much knowledge about how your platform works, and this will give a poor abstration experience to your customers.
You need to consider your abstractions carefully. Backstage should be responsible for the “View” aspect of the system, but controlling the backend system and orchestrating it, probably there is a better technology out there. Be very careful about putting too much platform responsibility into Backstage.
A better architecture to use with Backstage would separate, clearly, the “View” of your platform from your backend system. A better Backstage architecture can be seem below:
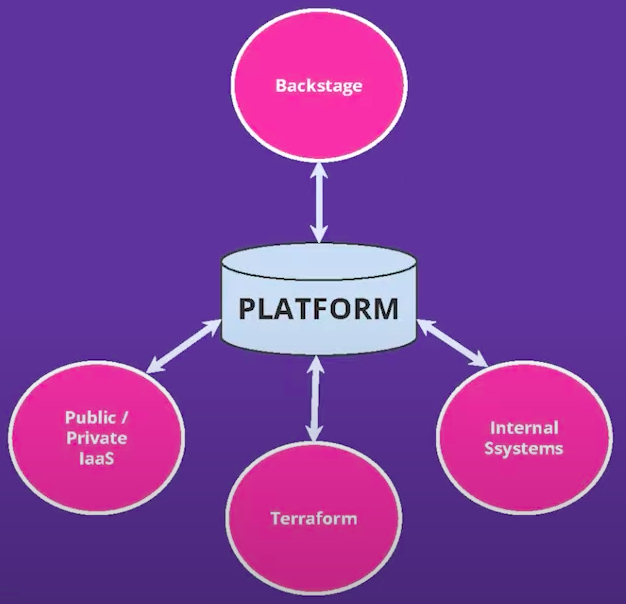
This way, Backstage can serve as declarative framework and a View to your platform abstractions. Backstage will not be responsible to have all platform knowledge, because the Platform layer will have it and expose abstractions that can be consumed by Backstage.
To wrap things up, it is important to selected the high tools, abstractions and consider your investments in the platform team. Your platform team should always decide and invest in:
- Serve your users
- Increase your organisational speed
- Keep your teams cognitive load low
The power of collaboration: Why platform engineers should engage in open source contributions
Contributing to Open Source makes you a better engineer. That’s because you need to create generic solutions (not vendor-specific), it will force you to read the existing code before writing, and the impact is huge – because a lot of different companies will use your contributions.
Besides that, it will push you to practice public speaking, helps your career and personal brand grow, improves communication and confidence, and you will meet a lot of great people.
You can prioritise feature that are important for your use cases, less in-house tailoring (as you will fix things in the project itself).
The company that gives time for the employees to contribute to Open Source also get benefits: the employees will bring back knowledge about the project, easier to attract talents to the team and can impact the project roadmap (which will bring more value to the business).
Authorization at scale in platform environments
In the platform engineering space, there are multiple iniciatives that could be explored to help your internal customers. One of them is centralizing/standardizing the Authorization.
It is common to see every application implementing its own authorization logic, but this can be a problem at scale (hundreds of applications):
- Implementation errors (or lack of implementation)
- Not knowing which app validates AuthZ and which doesn’t
- With multiple types of authentication (cookie, access token, etc), each application will have to implement it separately
- Risk of session leak
- Implementation cost
- No enforcement point for security
To solve this problem, the internal platform could offer AuthZ as a Service.
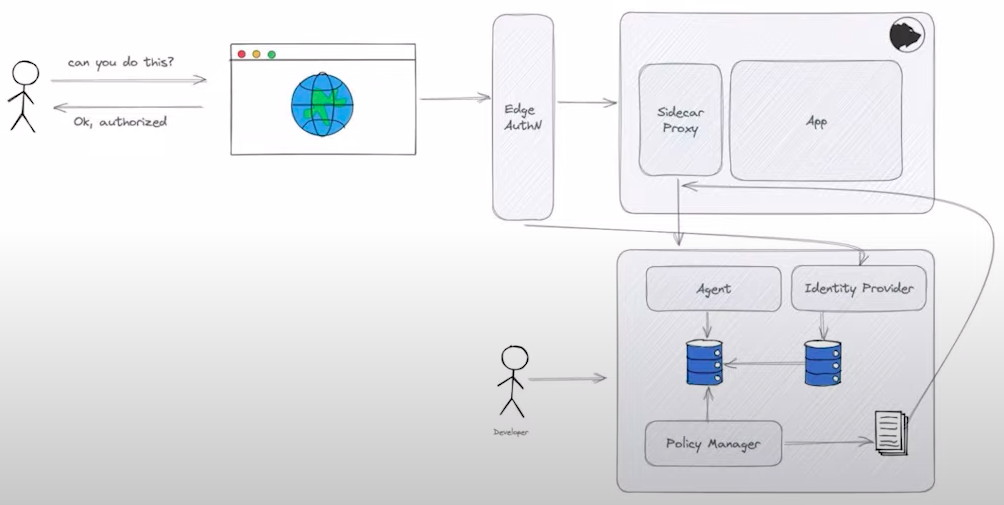
The image above is a simplified sample design of an AuthZ as a Service. Each application doesn’t have to implement AuthZ, this responsibility is outsourced to the internal platform. The pros of this approach are:
- Enforcement point for security
- Less responsibility for applications
- Increase velocity and impact of developers, as they can focus even more on feature that brings value to their Business Unit
- Standardization of AuthZ
- Hot deploy (it is possible to change AuthZ without redeploying the application)
- Traceability (how many requests (%) were denied and why)
Besides its benefits, it also has some cons:
- Cost of migrating to the new AuthZ method
- Major paradigm shift
- Complex implementation
Also, there are some learnings and concerns that should be highlighted:
- RBAC is not enough in many cases
- Paradigm transition can be a challenge
- The AuthZ service needs to be highly performant
- Critical component in the infrastructure, needs to have high resilience to not become a single point of failure
It’s important to reinforce that Authorization must be a high security concern to the company. The OWASP Top Ten Application Security Risks states that Broken Access Control is the number one security risk.
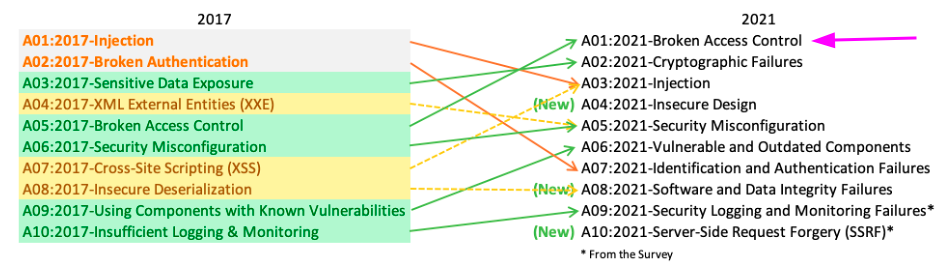
Having Authorization as a Service in the internal platform brings long-term gains in security, scalability and standardization to the company. Also, don’t limit your AuthZ as a Service solution to RBAC, it is important to support other types of AuthZ.
Drift detection in multi-region AWS deployments for enterprises using DriftCTL
In larger enterprises, it is common to have multi-region and multi-accounts in AWS. The infrastructure is created using IaC, but it is common to see IaC drift when incidents occur. When the cloud provider has drift, this can generate security risks, as the cloud state is not the same as the IaC in the repositories.
The tool DriftCTL will compare the Terraform state and the resources in AWS. When you run a driftctl scan, it will output how many resources are managed by Terraform, how many aren’t, how many is declared in Terraform state but missing on the cloud provider and the “coverage” of IaC in the account.
It is possible to define the output of the driftctl command as HTLM or JSON. Below is an example of the HTML generated:
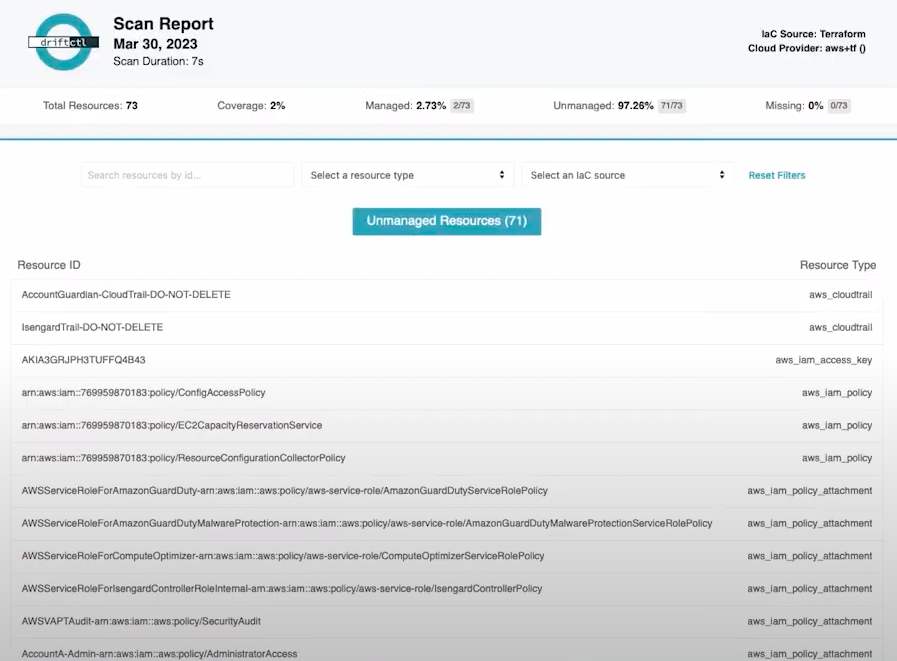
Each DriftCTL scan refers to one TFSTATE. Probably there are multiple TFSTATES that composes the whole cloud provider configuration. Because of that, there is a Python script that collapses all outputs in one. Below is the example of this Python output from multiple accounts and regions (multiple TFSTATES).
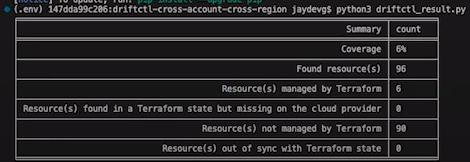
As you can see in the image above, there is no drift in the cloud provider. So we will introduce a drift, run driftctl and the python script again, the only difference is that we will use the python script with the --detailed flag. The new output would be:
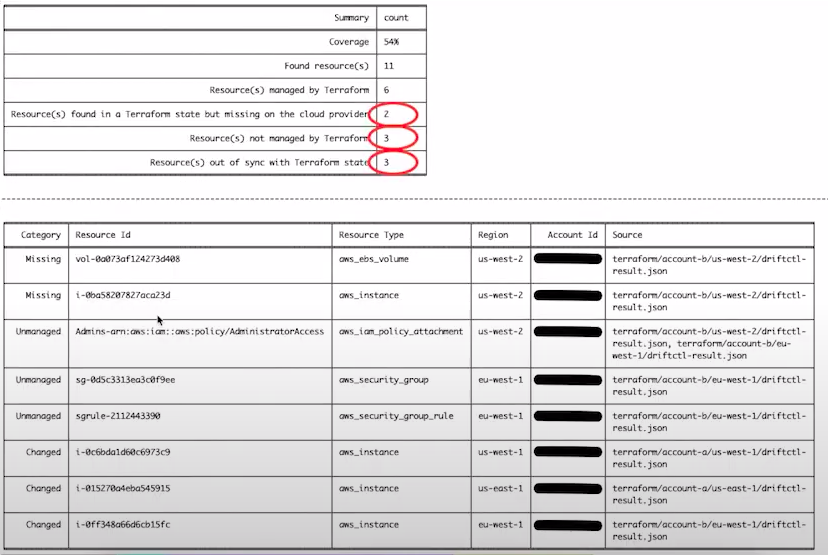
This tool can be used in combination with a CronJob or the CI pipeline to generated reports frequently. Then, this reports could be analysed on the desired frequency (daily, weekly, etc) to take actions.
There is a blog post from AWS with a Hands-On to test DriftCTL: Reduce security risks from IaC drift in multi-Region AWS deployments with Terraform.
Shorten the feedback loop: How to optimize developer experience and system design
System Design and Developer Experience: often seem as two completely different things, but actually they have a lot in common. Both of them are designed to optimize your systems for change. Software Architecture is focused on optimizing your systems for change and DevEx is focused on optimizing your developer tooling, but both of them are focused around the ability to shorten the feedback cycle around either product or system changes.
We have the traditional SDLC, represented in the image below:
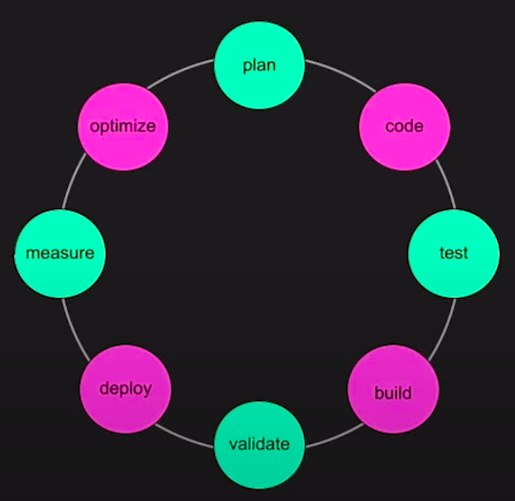
In DevEX, instead of designing your systems to adapt to change, you are developing platforms, automations and tooling for your developers to use to interact with the SDLC, making each part of the cycle easier.
Key-takeaways:
- Tech leads should consider DevEx in System Design.
For example, if a new event-driven stack in a new cloud provider is used, we should consider how to debug, test and optimize it (DevEx). Those are things inherited by the System Design and should be considered, because requirements will change and you want to be able to respond to them quickly (debugging, testing and optimizing).
- System Design should be optimized for continual change.
The system will never stop changing, so you need to respond to that as they come up.
- Add scalability and performance to your DevEX tools.
Scalability and performance debugging should be core to the work of creating internal DevEx tools. It will enable service teams to measure performance, capacity analysis and cost on the code that are being developed. It will help service teams to answer important questions of the system design.
Why is it so hard to create a great Platform-as-a-Product?
Platform as a Product or Product thinking is something almost every person in the platform engineering space have heard. However, it seems much harder to do in practice than in theory. Here are some stumbling blocks when trying to do this product thinking:
- Not affording the platform the same considerations as an external product.
Because the customers of this platform are internal users, often times assumptions are made about them, such as: what is best for them, their abilities and willingness to accept what’s provided.
Another problem is treating the platform as a cost center. This can bring the risk of a cost cutting war and depriorisation, as it isn’t seem as a proper product.
To solve this, it is important to try to market the value of the platform. This can be done using metrics, for example, how long it takes to a new team onboard a new product and get it to market without the platform and with the platform. This can bring evidence that the platform really provide value.
- Making the platform mandatory
If you check other products, no one forces you to use them. We are not forced to choose a specific cloud provider, a brand of shoes or a phone, we choose one because we decided that it is worth it.
With an optional approach, users will give feedbacks, discussions and this will improve innovation and the user experience. By making the platform mandatory, you will cut this valuable feedback loops.
- Optimising for a “MonoPlatform”
Platforms are often designed to “rule them all” and offer one way of doing things. This can be problematic, as each team and application has a different contexts, use cases and needs.
- Working within less than ideal team shapes & markeups
Because platforms are often created by infra-biased teams, the solutions built are more “opsy”. Teams that build the platform should be “bilingual”, speaking both app & infra, a mix of engineers that understands about architecture and application requirements as well as infrastructure skills.
Another thing, that is not essential but massively helps, is having a technical product owner. When this PO has the technical knowledge, it can really help to build more natural empathy and understanding with the various different users of the platform in different situations.
- Having an unhealthy focus on the tech
As engineers, we tend to have an unhealthy focus on technology. Engineers always want to start by building something concrete instead of resisting the urge and focusing on the users needs first.
High-performing engineering teams and the Holy Grail
Analysing anonymous data from Puppet State of DevOps Report since 2019, a set of recommended baseline engineering metrics that relate to CI/CD were identified. It is important to note that metrics aren’t “One size fits all”, each application or team has different contexts and use cases. But, key similarities suggesting valuable benchmarks for teams to use as gols were identified:
- Duration: average time in minutes to move a unit of work through your pipeline. The benchmarks recommend to be less or equal to 10 minutes, in average.
- Mean time to recovery: average time to go from a failed build signal to a successful pipeline run. The benchmarks recommend to be less or equal 60 minutes on default branches.
- Success rate: number of passing runs divided by the total number of runs over a period of time. The benchmarks recommend to be more than 90% success rate in default branches.
- Throughput: average number of workflow runs that an organization completes on a given project per day. An ideal throughput is subjective to your organization goals.
Improving test coverage is a practice that we noticed that improved all metrics, for example:
- Add unit, integration, UI and end-to-end testing across all app layers.
- Incorporate code coverage tools into pipelines to identify inadequate testing.
- Include static and dynamic security scans to catch vulnerabilities.
- Incorporate TDD practices by writing tests during design phase.
To get a faster MTTR:
- Treat your default branch as the lifeblood of your project (and the company).
- Set up instant alerts for failed builds using services like Slack, Twilio, PagerDuty, etc.
- Write clear, informative error messages for your tests, allowing quick diagnosis.
🌟 How to implement a developer platform in an organization with hundreds of existing services
One of the challenges faced when building an IDP for a “enterprise level” company is “How to support many different tech stacks?”.
To tackle this problem, SAP created a “Fellowship program”. This program works like this:
- Engineers are recruited from across the organization and join the Platform Engineering Fellowship for 3-6 months. This engineers has different backgrounds, experiences and domain knowledge.
- They learn about Platform Engineering mission and the current IDP features.
- Help to build out the features under the guidance of engineers that are part of the team. This features are related to solve problems from the area that they worked before.
- Then, they take those features and integrate them back into the services from their area.
- Once they have done that, these engineers “demo” the work completed to another teams, area and the entire organization; which gives them the exposure and experience.
The benefits of this approach is:
- Brings together engineers with different skills & domain knowledge
- Opportunity for engineers to work on new technologies
- Helps with buy-in and adoption of Platform features
- Builds Platform Engineering community in the organization
- Ongoing contributions
Besides the challenge, they also used the following KPIs to measure the success of the platform:
- Adoption Figures: number of teams that have adopted features from the platform
- Dev time on OPS tasks: surveys to get how much time developers are spending on Ops and try to compare this time before & after the platform features
- Production Incidents: number of production incidents, MTTR and compare these numbers before & after the platform features, seeking to reduce the number and duration of incidents.
How to avoid burning your startup money on cloud costs!
To start off with FinOps, there are 4 main steps to implement it:
- Tag everything
Tag every resource by multiple dimensions, automate tagging with Terraform modules and insert validation to ensure that all resources in the cloud are tagged.
- Visibility
Use any tool to visualize cost. It can be the cloud provider tool itself (for example, AWS cost explorer) or any 3rd party system. It is important to have the desired visibility for you use case, that could be per tenant, service, etc.
- Tracking
Create reports, slack integration and alerts envolving your cloud costs expenses.
- Insights
Identify top spend factors, understand true cost and deep dive into services.
After that, the next things to be done is:
- Define a Goal (Where do we want to get)
- Yearly/monthly bill
- Percentage of savings
- Cost per tenant
- Understand Constraints (What can & can’t be done?)
- Must keep current SLA
- Application changes
- Developers experience
- Understand Business Unit cost (How should I really measure?)
- What happens if the company grows?
- What is the real business unit cost?
- How much does one tenant cost?
After all of that, you should drill down your cloud provider understanding of the cost for each type of resource. Your top spend factors are the major opportunity to shrink costs, and with the cloud provider knowledge, you could change the infrastructure configuration to minimize the bills.
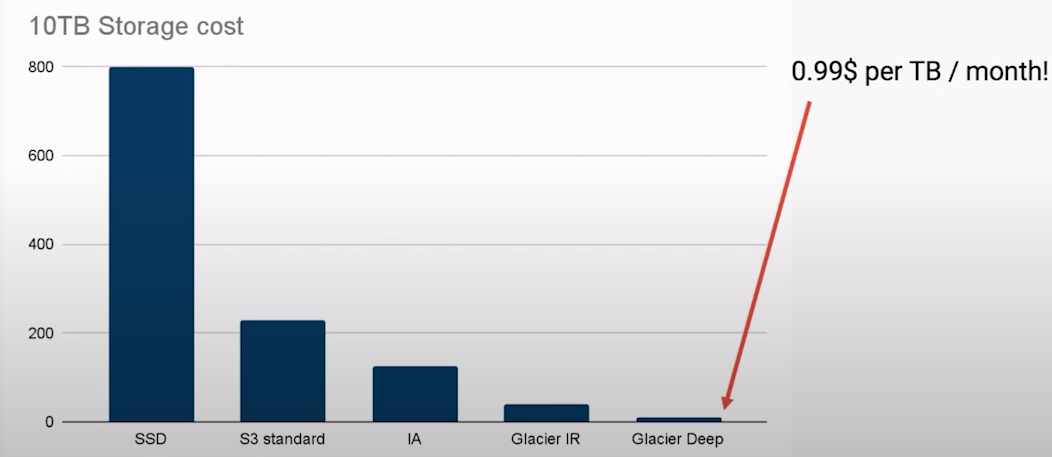
It is important to analyse each factor individually, what are the use cases for this infrastructure resource in your company and modify the configuration to reduce costs. For example, in S3 you can move infrequently accessed data to lower cost tiers:
Conclusion
PlatformCon is a great yearly conference in the Platform Engineering space. If you want to get closer to the community, join Slack and sign up for PlatformCon 2024!
If you have any questions, suggestions or want to discuss the topic even further, reach me out on Twitter!